- Contar con un plan y manuales de respuesta a incidentes reduce drásticamente el impacto técnico, legal y reputacional de un ciberataque.
- La gestión eficaz de incidentes exige un ciclo completo: preparación, detección, contención, erradicación, recuperación y análisis posterior.
- Equipos especializados (CSIRT, SOC) y servicios externos, junto con herramientas como SIEM, EDR y SOAR, permiten reaccionar con rapidez y precisión.
- Marcos, servicios nacionales como INCIBE-CERT y la mejora continua ayudan a usuarios y organizaciones a aumentar su resiliencia frente a futuras amenazas.
Vivimos pegados al móvil, al correo y a la nube, y eso tiene una cara B: los ciberataques ya no son cosa de películas, sino algo que cualquiera puede sufrir en casa o en el trabajo. Desde un simple correo de phishing hasta un ransomware que cifra todos tus archivos, el impacto puede ser enorme si no sabes qué hacer en los primeros minutos.
La buena noticia es que, aunque no seas técnico, puedes reaccionar mucho mejor si tienes claro un plan. Un buen esquema de respuesta a incidentes te ayuda a mantener la calma, saber a quién avisar, qué pasos seguir, cómo recuperar tus datos y qué aprender para que no vuelva a pasar. En este artículo vamos a desgranar, de forma cercana pero muy completa, cómo responder a ataques cibernéticos tanto si eres usuario particular como si formas parte de una organización.
Qué es realmente un ciberataque y por qué te afecta
Un ciberataque es, en esencia, una acción maliciosa contra un sistema, red o dispositivo con el objetivo de robar datos, alterarlos, destruirlos o dejar un servicio fuera de juego. Puede dirigirse contra un portátil, contra toda la red de una empresa o incluso contra infraestructuras críticas.
Las motivaciones van desde la búsqueda de dinero fácil (fraude, ransomware, robo de tarjetas) hasta el espionaje, la venganza de un empleado descontento o incluso campañas ideológicas. Entender qué es un hacker de sombrero negro ayuda a contextualizar muchas de estas amenazas.
Además, hay otra capa que a veces se olvida: el daño reputacional y las posibles consecuencias legales. Si una empresa maneja datos personales y sufre una brecha, puede enfrentarse a sanciones por incumplir regulaciones en ciberseguridad como el RGPD, perder la confianza de sus clientes y ver cómo su imagen pública se deteriora.
Tipos de incidentes y ataques que exigen una respuesta inmediata
No todos los incidentes de seguridad son iguales, pero hay una serie de ataques muy habituales que exigen actuar rápido si queremos reducir los daños.
Uno de los más conocidos es el acceso no autorizado. Aquí alguien entra donde no debe: en tu correo, en la intranet de tu empresa, en un servidor o en una base de datos. Suele ocurrir por robo de credenciales, contraseñas débiles, explotación de vulnerabilidades o abuso de permisos internos.
Relacionado con esto están las violaciones y fugas de datos. Se trata de incidentes en los que información sensible que debía permanecer protegida acaba expuesta, filtrada o directamente robada. A veces es fruto de un error de configuración o de malas prácticas; otras, de ataques como malware, fuerza bruta o phishing.
Tampoco hay que pasar por alto las amenazas internas. Pueden ser empleados, proveedores o personas con acceso legítimo que, por negligencia o mala fe, facilitan una brecha: desde copiar datos a un USB sin permiso hasta colaborar con atacantes externos. Aquí el problema no es solo técnico, sino también de procesos, controles y cultura de seguridad. La ciberhigiene para equipos no técnicos es clave para reducir estas incidencias.
Las violaciones de seguridad física son menos frecuentes, pero igual de graves: alguien entra en una oficina, centro de datos o sala de servidores y accede a dispositivos o soportes con información crítica. El robo de portátiles, móviles o discos externos sin cifrar puede acabar en un incidente de primer nivel; reforzar la seguridad de endpoints ayuda a mitigarlo.
Luego están los escenarios más técnicos como los ataques de día cero (vulnerabilidades desconocidas sin parche), el cryptojacking (uso oculto de tus recursos para minar criptomonedas), y por supuesto el malware y el ransomware, que pueden cifrar o destruir datos, robar información o abrir puertas traseras para nuevos ataques. Para mantenerse al día, consulta la actualidad de ciberseguridad.
Incidentes habituales en el día a día: phishing, ransomware, DDoS y más
Además de las categorías generales, es útil conocer escenarios concretos donde un buen plan de respuesta marca la diferencia.
Los ataques de ransomware cifran tus archivos o sistemas y piden un rescate. Aquí la velocidad lo es todo: aislar máquinas, bloquear la propagación y tener copias de seguridad sanas puede salvar tu negocio. La respuesta típica pasa por detección, contención, eliminación del ransomware, restauración de copias y análisis forense posterior.
Los ataques de phishing (correos o mensajes que suplantan a bancos, servicios o compañeros) siguen siendo el gran clásico. Una vez que alguien hace clic o entrega sus credenciales, se activa el manual de respuesta: identificar cuentas comprometidas, forzar cambio de contraseñas, revisar accesos, alertar a los usuarios y bloquear correos similares. Además, fortalecer la protección de identidad online reduce el impacto de estos engaños.
Las infecciones de malware pueden venir por descargas, adjuntos, webs comprometidas o software pirata. La respuesta suele implicar aislar dispositivos afectados, escanear con herramientas avanzadas, limpiar o reinstalar sistemas, revisar logs y mejorar la protección de endpoints; en especial, revisar la seguridad para Windows cuando los equipos afectados son PCs.
En el caso de aplicaciones comprometidas (por ejemplo, una web corporativa con una vulnerabilidad explotada), hay que aislar la aplicación afectada, corregir el fallo, revisar accesos y comprobar si se han exfiltrado datos. Aquí la coordinación entre desarrollo, sistemas y seguridad es clave. Revisar prácticas sobre vulnerabilidades de seguridad en sitios web ayuda a prevenir incidentes.
Los ataques de denegación de servicio distribuida (DDoS) apuntan a tirar abajo servicios online saturándolos de tráfico. El plan de respuesta incluye análisis y filtrado de tráfico, apoyo de proveedores de mitigación DDoS y comunicación clara con clientes mientras se restablece la normalidad.
Por último, las amenazas internas y el triaje de incidentes (clasificación y priorización) requieren procedimientos formales: investigar accesos, revisar actividades sospechosas y determinar qué incidente va primero para no perderse en el ruido.
Por qué es vital contar con un plan de respuesta a incidentes
Una organización sin plan de respuesta a incidentes va literalmente a ciegas en plena crisis. Cuando llega un ataque serio, las decisiones improvisadas bajo presión suelen empeorar las cosas: se oculta información, se comunica mal, se incumplen leyes o se toman medidas técnicas erróneas.
Un plan de respuesta a incidentes bien diseñado reduce drásticamente el tiempo de detección, contención y recuperación, limita las pérdidas económicas, ayuda a cumplir regulaciones de protección de datos, mantiene la confianza de clientes y socios y, en definitiva, sostiene la continuidad del negocio.
Desde el punto de vista de gestión de riesgos, este plan funciona como red de seguridad: no evitará todos los ataques, pero sí reducirá muchísimo su impacto. Además, es una pieza clave para demostrar ante organismos reguladores que se toman medidas razonables para proteger datos personales.
Otro aspecto que suele pasar desapercibido es la mejora continua. Cada incidente deja lecciones valiosas: procesos que fallaron, herramientas que no detectaron a tiempo, falta de formación en un equipo concreto. Si se documenta bien y se integra en el plan, la organización sale más fuerte.
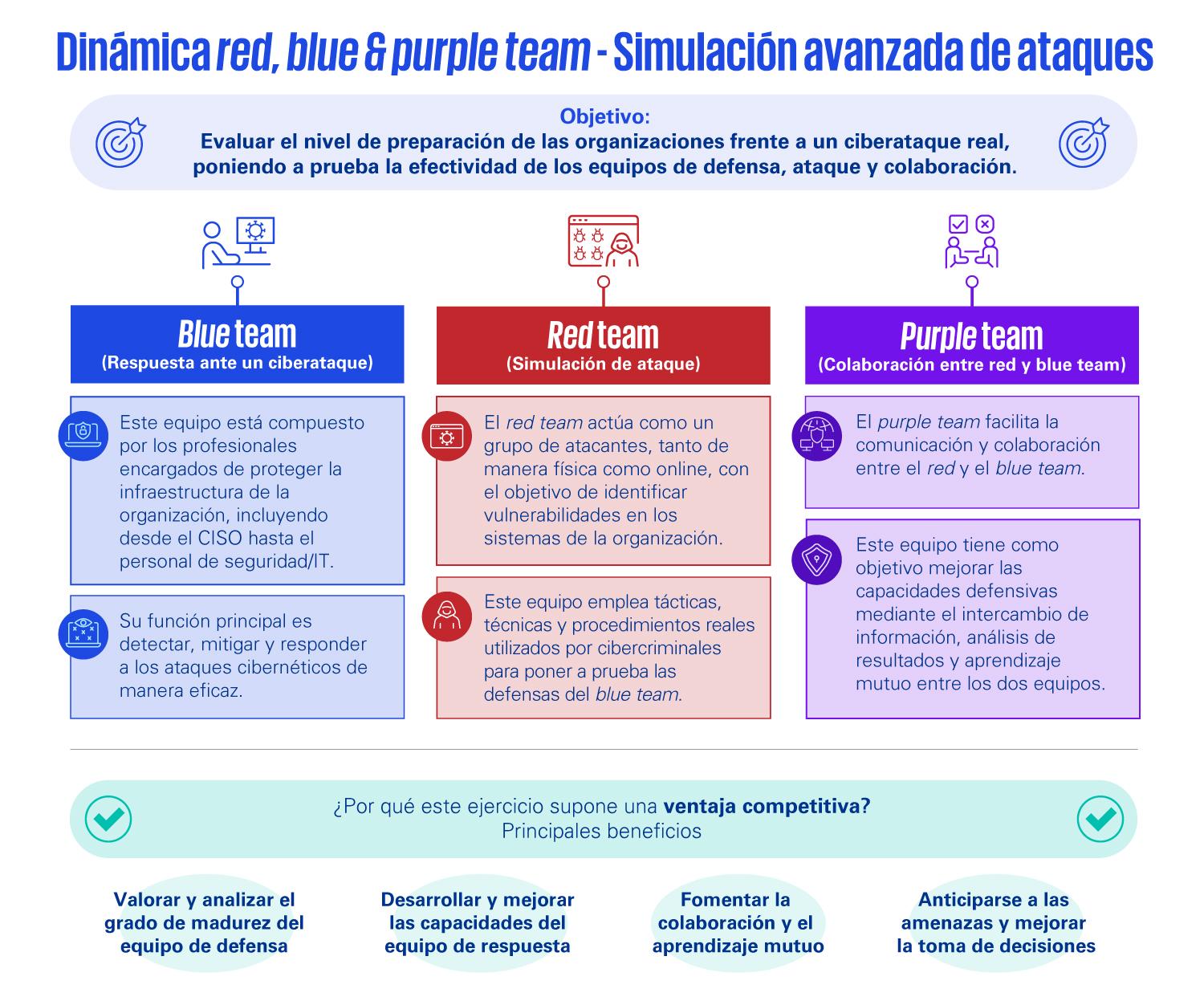
Equipos y roles: CSIRT, SOC y servicios especializados
Los planes no se ejecutan solos. Las organizaciones maduras cuentan con un CSIRT (Computer Security Incident Response Team) o equipo de respuesta a incidentes, que se apoya muchas veces en un SOC (Security Operations Center) y otros departamentos.
En este equipo suelen participar el CISO o responsable de seguridad, analistas de SOC, personal de TI y sistemas, expertos de negocio, comunicación, legal, cumplimiento normativo, recursos humanos y, en ocasiones, proveedores externos de servicios de ciberseguridad.
Sus responsabilidades incluyen diseñar y mantener los planes y manuales de respuesta, coordinar las actuaciones durante un incidente, recopilar y conservar evidencias (pensando también en posibles acciones legales) y liderar el análisis posterior al incidente para introducir mejoras.
Muchas empresas complementan su CSIRT interno con socios externos especializados en respuesta a incidentes. Estos pueden aportar monitorización 24/7, herramientas avanzadas, experiencia forense o apoyo específico en incidentes complejos como ransomware a gran escala o ataques a la nube.
Servicio nacional de ayuda y CERT: apoyo para usuarios y empresas
En España, los usuarios no están solos. INCIBE-CERT y el servicio Tu Ayuda en Ciberseguridad ofrecen soporte gratuito, confidencial y personalizado tanto a ciudadanos como a empresas, profesionales y menores (junto con sus familias y educadores).
Por un lado, INCIBE-CERT recibe incidentes a través de buzones específicos, pero también emplea técnicas de anticipación y detección temprana: correlaciona múltiples fuentes de información para identificar campañas activas, lanzar avisos, elaborar alertas y notificar a los afectados incluso antes de que estos se den cuenta.
En el ámbito del fraude online, dedican especial atención a los dominios .es, trabajando codo con codo con dominios.es. La colaboración de los usuarios es esencial para bloquear contenidos fraudulentos con rapidez y reducir el impacto sobre las potenciales víctimas.
Por otro lado, el servicio Tu Ayuda en Ciberseguridad de INCIBE está operativo todos los días del año, de 8 de la mañana a 11 de la noche, y lo atiende un equipo multidisciplinar que puede dar asesoramiento técnico, psicosocial y legal sobre problemas de ciberseguridad del día a día.
Fases del ciclo de vida de la respuesta a incidentes
Los marcos de referencia más utilizados (como NIST) dividen la respuesta a incidentes en varias fases encadenadas que ayudan a organizar el trabajo y no dejar cabos sueltos.
La primera fase es la preparación. Aquí se definen políticas, se identifican activos y riesgos, se elige la tecnología necesaria (SIEM, EDR/XDR, copias de seguridad, herramientas forenses…), se crea el equipo de respuesta y se establecen los canales de comunicación internos y externos.
La segunda fase es la detección e identificación. Incluye la monitorización continua, la identificación de indicadores de compromiso (IoC), la gestión de alertas, el análisis de logs y la priorización de incidentes según su impacto y urgencia.
La tercera fase agrupa contención, mitigación y erradicación. Primero se frena el ataque (aislando sistemas, cambiando credenciales, bloqueando IP maliciosas), luego se corrigen vulnerabilidades, se eliminan artefactos maliciosos y se limpian sistemas comprometidos.
La cuarta fase es la recuperación: restaurar servicios y datos, validar que todo funciona y que no queda rastro de la amenaza, y devolver la operación a un estado estable.
Por último, está la fase de actividad posterior al incidente: análisis en profundidad de lo ocurrido, documentación, informe detallado, revisión de métricas (tiempos de detección, contención y recuperación) y actualización del plan y de las medidas técnicas y organizativas.
Cómo se estructura un plan de respuesta a incidentes eficaz
Un plan de respuesta a incidentes serio va mucho más allá de un documento genérico. Debe adaptarse al entorno concreto de la organización y contemplar los tipos de incidentes más probables.
Entre sus elementos clave encontramos un plan de comunicaciones (quién informa a directivos, empleados, clientes, medios y autoridades), instrucciones para recopilar y documentar información y evidencias, y la descripción clara de los responsables y los procesos de escalado.
Es habitual que existan planes específicos para distintos tipos de ataques: DDoS, ransomware, malware, amenazas internas, phishing dirigido, incidentes en la nube, etc. Cada uno requiere matices distintos en la respuesta.
Este plan debe ser a la vez detallado y flexible. Si es demasiado rígido, se quedará corto ante escenarios imprevistos; si es demasiado vago, no servirá de guía en el momento de la verdad. Además, conviene revisarlo al menos cada seis meses o después de cada incidente significativo.
Manual o playbook de respuesta: la guía paso a paso
Junto al plan general, es muy útil contar con manuales de respuesta a incidentes (playbooks) para escenarios concretos. Un manual describe una serie de acciones que se ejecutarán cuando se produzca un evento específico, y está muy ligado a la automatización de seguridad y a soluciones SOAR.
Cada manual incluye una condición de inicio (la alerta o evento que lo dispara), los pasos de proceso imprescindibles (las acciones obligatorias para mitigar el incidente), actividades opcionales (buenas prácticas adicionales), el estado final deseado y la relación con requisitos regulatorios o de gobernanza.
Para crearlos, primero se definen los tipos de incidentes y sus desencadenantes (por ejemplo, un correo marcado como phishing, un endpoint con ransomware, un pico de tráfico anómalo en un servicio web). Después se listan todas las acciones posibles, se distinguen las obligatorias de las opcionales y se construye el flujo central usando solo las obligatorias.
Más tarde se integran las actividades opcionales en puntos lógicos del flujo (por ejemplo, enriquecer información de amenazas, notificar a ciertos equipos, ampliar monitorización) y se documentan con criterios claros: cuándo se realizan, quién las ejecuta y qué se espera de cada una.
Por último, cada playbook establece estados de cierre (resuelto, mitigado, escalado a otro equipo, derivado a otro manual) y detalla las obligaciones de reporte (por ejemplo, plazos de notificación a la autoridad de protección de datos o a clientes afectados).
Herramientas y tecnologías para gestionar incidentes
Para que todo lo anterior no se quede en teoría, las organizaciones necesitan un conjunto de herramientas de seguridad bien integradas.
Las soluciones de seguridad para endpoints (EDR/XDR) monitorizan continuamente los dispositivos, detectan comportamientos sospechosos, bloquean malware, aíslan máquinas y proporcionan telemetría para investigar incidentes. Son la primera línea contra muchas amenazas modernas.
Las plataformas SIEM recopilan y correlacionan registros de múltiples sistemas (firewalls, servidores, aplicaciones, bases de datos, dispositivos de red) para detectar patrones anómalos, generar alertas y facilitar la investigación forense. Cada vez más, incorporan IA para reducir falsos positivos y priorizar incidentes.
Las plataformas de inteligencia de amenazas aportan contexto: listas de IP maliciosas, dominios sospechosos, campañas activas, indicadores conocidos de malware, etc. Esto permite enriquecer las detecciones y tomar decisiones más informadas.
Además, las soluciones de orquestación, automatización y respuesta (SOAR) permiten automatizar tareas repetitivas: revisar fuentes de inteligencia, abrir y actualizar tickets, enviar alertas por correo, recolectar métricas, bloquear IP, aislar endpoints, etc. Cada paso automatizado ahorra minutos vitales en un incidente real.
Respuesta a incidentes en la nube: retos específicos
Los entornos en la nube añaden complejidad a todo este esquema. La arquitectura distribuida, la elasticidad y los modelos de responsabilidad compartida obligan a adaptar los procesos tradicionales de respuesta a incidentes.
Uno de los principales desafíos es la visibilidad: recursos efímeros que aparecen y desaparecen, múltiples regiones geográficas, servicios gestionados por terceros… Todo esto complica la recolección de evidencias y el análisis forense.
Es crucial acordar con el proveedor de nube cómo se va a acceder a registros, tráfico y snapshots durante una investigación, y qué partes del proceso asume cada uno. También conviene automatizar acciones de contención mediante políticas y controles basados en infraestructura como código y API.
Los escenarios típicos en la nube incluyen robo de credenciales, explotación de configuraciones erróneas (buckets públicos, claves expuestas, puertos abiertos) y secuestro de recursos para actividades como el cryptojacking. Los equipos deben entrenar específicamente este tipo de casos.
Cómo medir si tu estrategia de respuesta funciona
No basta con tener planes y herramientas; hace falta comprobar en la práctica si la estrategia funciona. Para ello se emplean ejercicios operativos, simulaciones y métricas claras.
Los ejercicios prácticos y simulacros ponen a prueba a los equipos en escenarios realistas: desde ataques de ransomware hasta fugas de datos o caídas de servicios críticos. Se evalúa cómo detectan, cómo comunican, qué decisiones toman y cuánto tardan en restablecer la normalidad.
Las pruebas basadas en debates (tabletop) permiten recorrer un incidente de forma teórica, detectando huecos en procesos, fallos de coordinación o falta de claridad en roles y responsabilidades, sin necesidad de tocar sistemas reales.
En cuanto a métricas, se suelen monitorizar indicadores como el tiempo medio de detección (MTTD), el tiempo medio de contención, el tiempo medio de recuperación, la frecuencia de incidentes, el coste asociado por incidente y el número de escalados o fallos de comunicación.
Cuándo tiene sentido externalizar la respuesta a incidentes
No todas las organizaciones cuentan con personal, conocimientos o presupuesto suficientes para montar un equipo de respuesta interno completo. Externalizar parte o todo el servicio de respuesta a incidentes puede ser una opción muy razonable.
Los proveedores especializados ofrecen cobertura 24/7, experiencia en sectores concretos, acceso a herramientas avanzadas sin grandes inversiones iniciales, y apoyo para cumplir estándares como ISO 27001 o marcos del NIST.
También aportan visión imparcial sobre el estado real de la seguridad de la organización, ayudan a priorizar inversiones, mejoran los procedimientos internos y, en caso de incidente grave, acortan sensiblemente los tiempos de reacción y recuperación.
En entornos especialmente complejos o críticos (infraestructuras esenciales, grandes volúmenes de datos personales, servicios en la nube a gran escala), contar con este tipo de servicios puede marcar la diferencia entre una crisis controlada y un desastre prolongado.
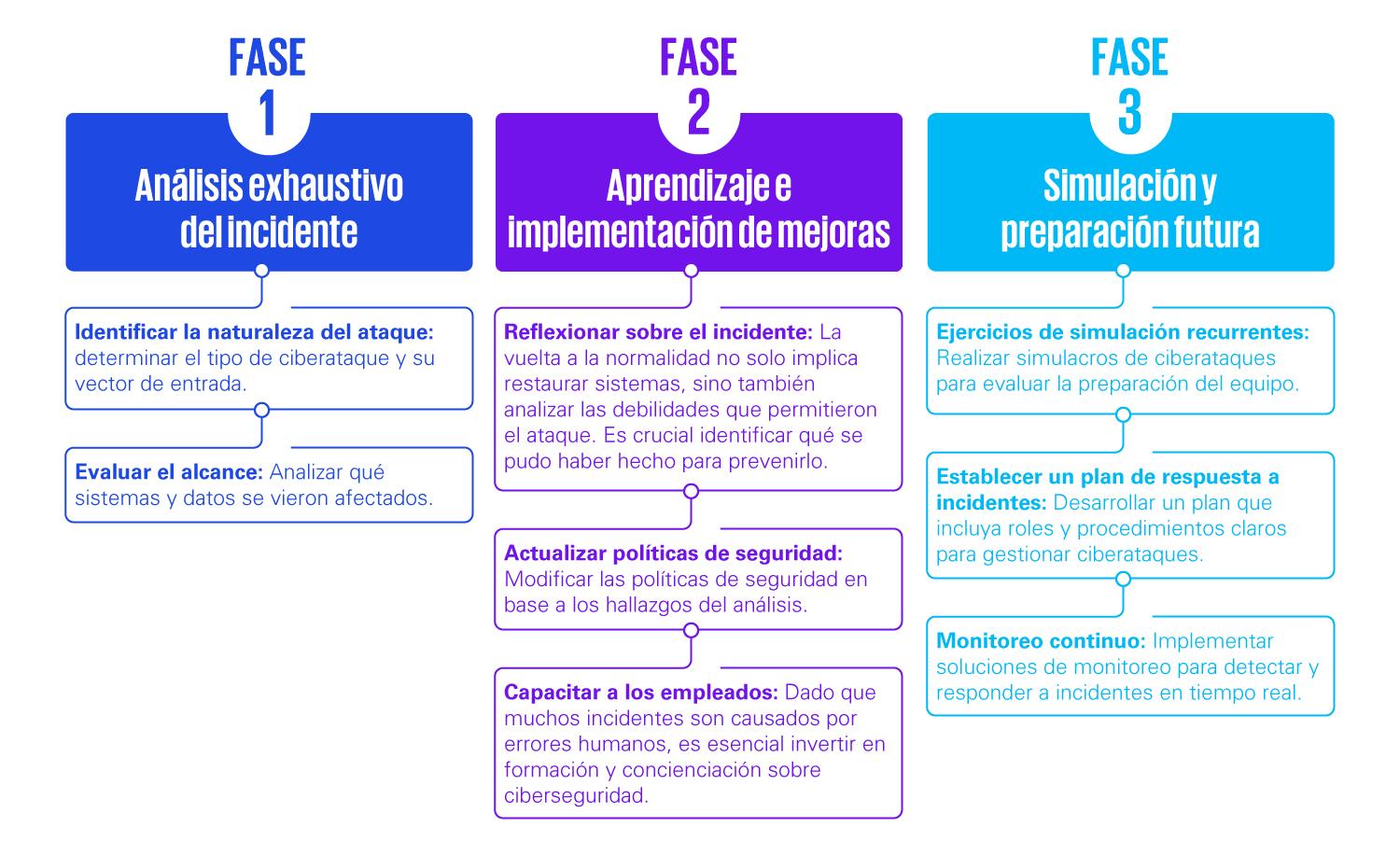
Caso práctico: impacto real y lecciones de grandes incidentes
La teoría se entiende mejor cuando se contrasta con la realidad. Algunos incidentes masivos de los últimos años ilustran la importancia de una buena (o mala) respuesta.
En el caso de Equifax (2017), una vulnerabilidad de aplicación web no parcheada permitió el acceso no autorizado a datos de unos 147 millones de personas durante semanas. La respuesta implicó segregar sistemas, análisis forense profundo y una larga gestión de daños reputacionales y regulatorios.
La brecha de Target (2013), que afectó a 41 millones de clientes, obligó a la empresa a reforzar monitorización, segmentar mejor su red y crear un centro de fusión cibernética para reaccionar más rápido a futuras amenazas.
El ataque NotPetya contra Maersk obligó a reconstruir miles de servidores y decenas de miles de equipos en tiempo récord, manteniendo operaciones parciales mediante procesos manuales improvisados. Esto mostró el valor de tener copias de seguridad robustas y planes de continuidad del negocio realistas.
En el ataque a la cadena de suministro de SolarWinds, la respuesta incluyó desarrollar esquemas sofisticados de categorización de incidentes, poner en cuarentena redes comprometidas y crear herramientas de detección específicas para un ataque extremadamente complejo y sigiloso.
Estos casos demuestran que, aunque nadie está a salvo de sufrir un ataque avanzado, la preparación, la transparencia y la capacidad de respuesta marcan una enorme diferencia en el impacto final sobre la organización y sus usuarios.
Los ciberataques seguirán aumentando en número y sofisticación, pero disponer de un plan de respuesta sólido, un equipo preparado (interno o externo), herramientas adecuadas y una cultura de mejora continua convierte lo que podría ser un caos absoluto en una situación difícil pero gestionable; tanto usuarios individuales como organizaciones pueden afrontar mejor estos incidentes si entienden los tipos de ataques, las fases de la respuesta, la importancia de la comunicación y el valor de apoyarse en servicios especializados y marcos reconocidos para proteger sus sistemas, sus datos y su reputación digital.
